
Зміст

Джерело: Kran77 / Dreamstime.com
Винос:
Моделі глибокого навчання вчать комп'ютери мислити самостійно, маючи дуже цікаві та цікаві результати.
Глибоке навчання застосовується у все більшій кількості областей та галузей. З автомобілів без водіїв, до гри Go, до створення музики зображень, щодня виходять нові моделі глибокого навчання. Тут ми переглядаємо кілька популярних моделей глибокого навчання. Вчені та розробники беруть ці моделі та модифікують їх новими та творчими способами. Ми сподіваємось, що ця вітрина може надихнути вас побачити, що можливо. (Щоб дізнатися про досягнення штучного інтелекту, перегляньте статтю, чи зможуть комп’ютери наслідувати людський мозок?)
Нейронний стиль
Ви не можете покращити свої навички програмування, коли ніхто не піклується про якість програмного забезпечення.
Нейронний Розповідач

Neural Storyteller - це модель, яка, даючи зображення, може генерувати романтичну історію про зображення. Це весела іграшка, і все ж ви можете уявити собі майбутнє і побачити напрямок, в якому рухаються всі ці моделі штучного інтелекту.

Вищевказана функція - це операція "змінення стилю", яка дозволяє моделі переносити стандартні підписи зображень до стилю розповідей з романів. Зміна стилю була натхненна "Нейронним алгоритмом художнього стилю".
Дані
Існують два основних джерела даних, які використовуються в цій моделі. MSCOCO - це набір даних від Microsoft, що містить близько 300 000 зображень, при цьому кожне зображення містить п'ять підписів. MSCOCO - це єдині використовувані дані, що контролюються, тобто це єдині дані, куди люди повинні були зайти і чітко виписати заголовки для кожного зображення.
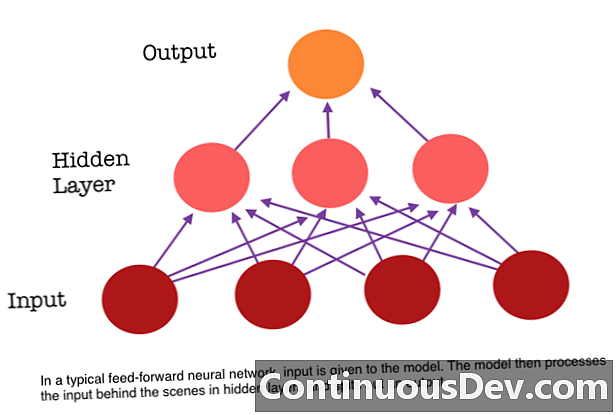
Одне з головних обмежень нейронної мережі, що рухається вперед, - це те, що вона не має пам'яті. Кожне передбачення не залежить від попередніх обчислень, наче це було першим і єдиним прогнозом, який мережа коли-небудь робила. Але для багатьох завдань, таких як переклад речення або абзацу, вхідні дані повинні складатися з послідовних та взаємозалежних даних. Наприклад, було б важко осмислити одне слово в реченні без конфірмації, що надається оточуючими словами.
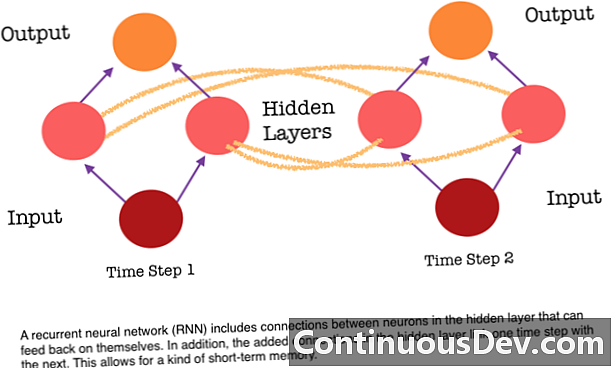
RNN відрізняються тим, що вони додають інший набір зв’язків між нейронами. Ці посилання дозволяють активації нейронів у прихованому шарі повертатися в себе на наступному кроці послідовності. Іншими словами, на кожному кроці прихований шар отримує як активацію з шару під ним, так і з попереднього кроку в послідовності. Ця структура по суті надає рецидивуючу пам'ять нейронних мереж. Отже, для завдання виявлення об'єкта RNN може спиратися на свої попередні класифікації собак, щоб допомогти визначити, чи є поточне зображення собакою.
Char-RNN TED
Ця гнучка структура в прихованому шарі дозволяє RNN бути дуже хорошими для мовних мов на рівні символів. Char RNN, спочатку створений Андреєм Карпаті, - це модель, яка бере один файл як вхідний і тренує RNN, щоб навчитися передбачати наступний символ у послідовності. RNN може генерувати символи за символом, які будуть схожі на вихідні дані тренувань. Демонстрація демонструється за допомогою стенограми різних TED-розмов. Подайте модель одним або декількома ключовими словами, і це створить уривок про ключові слова (слова) в голосі / стилі TED Talk.
Висновок
Ці моделі демонструють нові прориви в машинному інтелекті, які стали можливими завдяки глибокому навчанню. Глибоке навчання показує, що ми можемо вирішити проблеми, які ми ніколи раніше не могли вирішити, і ми ще не дійшли до цього плато. Очікуйте побачити ще багато захоплюючих речей, як автомобілі без водіїв, протягом наступних двох років в результаті глибокого вивчення інновацій.