
Зміст
- Клуб скептиків
- Конволюційні нейронні мережі (CNN)
- Ні помилок, ні стресу - покроковий посібник зі створення програмного забезпечення, що змінює життя, не руйнуючи ваше життя
- Одиниці довготривалої пам'яті (LSTM)
- Генеративні змагальні мережі (GAN)
- Висновки

Джерело: Vs1489 / Dreamstime.com
Винос:
Чи є "глибоке навчання" лише іншою назвою для просунутих нейронних мереж, чи є в цьому більше? Ми розглянемо останні досягнення в галузі глибокого навчання, а також нейронні мережі.
Клуб скептиків
Якщо ви, як і я, належите до клубу скептиків, ви також могли б поцікавитися, у чому вся суєта з приводу глибокого навчання. Нейронні мережі (НН) - це не нова концепція. Багатошаровий перцептрон був введений у 1961 році, що не зовсім вчора.
Але сучасні нейронні мережі є складнішими, ніж просто багатошаровий перцептрон; вони можуть мати ще багато прихованих шарів і навіть повторювані з'єднання. Але тримайте, чи вони все ще не використовують алгоритм зворотного розповсюдження для навчання?
Так! Тепер обчислювальна потужність машини незрівнянна з тією, що була доступна у 60-ті чи навіть у 80-ті. Це означає, що набагато складніші нейронні архітектури можуть бути навчені у розумний час.
Отже, якщо концепція не нова, чи може це означати, що глибоке навчання - це лише купа нейромереж на стероїдах? Чи все суєта викликана паралельними обчисленнями та більш потужними машинами? Часто, коли я розглядаю так звані рішення глибокого навчання, це так виглядає. (Які практичні реальні можливості використання нейронних мереж? Дізнайтеся у 5 випадках використання нейронної мережі, які допоможуть вам краще зрозуміти технологію.)
Як я вже казав, я належу до клубу скептиків, і зазвичай насторожено стаюсь ще не підтвердженими доказами. Одного разу давайте відкинемо забобони, і спробуємо всебічно дослідити нові технології, що розвиваються в глибокому навчанні щодо нейронних мереж, якщо такі є.
Коли ми копаємо трохи глибше, ми знаходимо кілька нових підрозділів, архітектур та прийомів у галузі глибокого навчання. Деякі з цих нововведень мають меншу вагу, як рандомізація, введена шаром, що випадає. Однак деякі інші відповідальні за більш важливі зміни. І, безумовно, більшість з них покладаються на більшу доступність обчислювальних ресурсів, оскільки вони обчислювально дорогі.
На мою думку, у галузі нейромереж було внесено три основні нововведення, які значною мірою сприяли глибокому навчанню, що набирає його сьогоднішньої популярності: конволюційні нейронні мережі (CNN), одиниці довготривалої пам'яті (LSTM) та генеративні змагальні мережі (GANs). ).
Конволюційні нейронні мережі (CNN)
Великий удар глибокого навчання - або, принаймні, коли я почув бум вперше - трапився в проекті розпізнавання зображень, масштабне візуальне розпізнавання Challenge ImageNet, у 2012 році. Для того, щоб автоматично розпізнавати зображення, створена згорткова нейронна мережа було використано вісім шарів - AlexNet. Перші п’ять шарів представляли собою звивисті шари, деякі з них супроводжувались максимальним об'єднанням шарів, а останні три шари були повністю з’єднаними шарами, усі з функцією активації ReLU, що не насичує. Мережа AlexNet досягла п’ятірки помилок на 15,3%, що на 10,8 відсоткових пунктів нижче, ніж у другого. Це було чудовим досягненням!
Ні помилок, ні стресу - покроковий посібник зі створення програмного забезпечення, що змінює життя, не руйнуючи ваше життя

Ви не можете покращити свої навички програмування, коли ніхто не піклується про якість програмного забезпечення.
Окрім багатошарової архітектури, найбільшим нововведенням AlexNet був звитий шар.
Перший шар конволюційної мережі - це завжди згортковий шар. Кожен нейрон у згортковому шарі фокусується на певній ділянці (сприйнятливому полі) вхідного зображення і через його зважені зв’язки діє як фільтр для сприйнятливого поля. Після ковзання фільтра, нейрона за нейроном, над усіма сприйнятливими полями зображення, на виході згорткового шару виробляється карта активації або карта функції, яка може використовуватися як ідентифікатор функції.
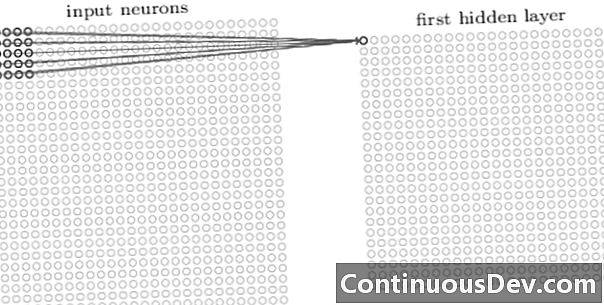
Додаючи більше згорткових шарів один на одного, карта активації може представляти все більш складні функції вхідного зображення. Крім того, часто в архітектурній мережі нейромережі ще кілька шарів перемежовуються між усіма цими згортковими шарами, щоб збільшити нелінійність функції відображення, поліпшити надійність мережі та контролю над надлишком.
Тепер, коли ми можемо виявити особливості високого рівня з вхідного зображення, ми можемо додати один або більше повністю пов'язаних шарів до кінця мережі для традиційної класифікації. Ця остання частина мережі приймає вихід згорткових шарів як вхідний і виводить N-мірний вектор, де N - кількість класів. Кожне число цього N-мірного вектора представляє ймовірність класу.
Ще в той день я часто чув заперечення нейронних мереж щодо непрозорості їх архітектури та неможливості інтерпретувати та пояснювати результати. Це заперечення сьогодні виникає все рідше і рідше у зв'язку з мережами глибокого навчання. Схоже, зараз прийнятно торгувати ефектом чорного поля для більшої точності в класифікації.
Одиниці довготривалої пам'яті (LSTM)
Ще одне велике вдосконалення, отримане завдяки нейронним мережам глибокого навчання, було помічено в аналізі часових рядів за допомогою періодичних нейронних мереж (RNN).
Повторні нейронні мережі - це не нова концепція. Вони вже використовувались у 90-х і навчалися за алгоритмом зворотного розповсюдження через час (BPTT). Однак у 90-х їх часто не можна було навчити, враховуючи кількість необхідних обчислювальних ресурсів. Однак нині, завдяки збільшенню наявної обчислювальної потужності, стало можливим не тільки підготовка RNN, але й підвищення складності їх архітектури. Це все? Ну, звичайно, ні.
У 1997 році було запроваджено спеціальний нейронний блок для кращого впорядкування запам'ятовування відповідного минулого в часовому ряду: LSTM-одиниця. Завдяки поєднанню внутрішніх воріт, блок LSTM здатний запам'ятати відповідну минулу інформацію або забути нерелевантний попередній вміст у часовій серії. Мережа LSTM - це особливий тип рецидивуючої нейронної мережі, включаючи одиниці LSTM. Розгорнута версія RNN на основі LSTM показана на малюнку 2.
Для подолання проблеми з обмеженою здатністю довгої пам'яті блоки LSTM використовують додатковий прихований стан - стан комірки C (t) - похідне від початкового прихованого стану h (t). C (t) представляє мережеву пам'ять. Конкретна структура, що називається воротами, дозволяє видалити (забути) або додати (запам'ятати) інформацію до стану комірок C (t) на кожному кроці часу на основі вхідних значень x (t) і попередній прихований стан h (t − 1). Кожен затвор вирішує, яку інформацію додати чи видалити, вивівши значення між 0 та 1. Шляхом множення виходу затвора вгору на стан комірки C (t − 1), інформація видаляється (вихід воріт = 0) або зберігається (вихід ворота = 1).
На малюнку 2 ми бачимо мережеву структуру блоку LSTM. Кожен блок LSTM має три ворота. Шар заходу забути на початку фільтрує інформацію з попереднього стану комірок C (t − 1) на основі поточного вводу x (t) і прихований стан попередньої комірки h (t − 1). Далі, комбінація «вхідного шару воріт» і «шару тану» визначає, яку інформацію додати до попереднього, вже відфільтрованого, стану комірки C (t − 1). Нарешті, останній затвор, «вихідний хвірт», визначає, яка з інформації з оновленого стану комірки C (t) закінчується в наступному прихованому стані год (т).
Щоб отримати детальнішу інформацію про модулі LSTM, перегляньте публікацію в блозі GitHub «Розуміння мереж LSTM» Крістофера Олаха.
Малюнок 2. Структура клітини LSTM (відтворена з "Глибокого навчання" Ian Goodfellow, Yhhua Bengio та Aaron Courville). Помітьте три ворота в одиницях LSTM. Зліва направо: ворота забуття, вхідні ворота та вихідні ворота.
Підрозділи LSTM успішно використовуються в ряді завдань прогнозування часових рядів, але особливо в розпізнаванні мови, природній обробці мови (NLP) та вільному генеруванні.
Генеративні змагальні мережі (GAN)

Генеративна змагальна мережа (GAN) складається з двох глибоких навчальних мереж, генератора та дискримінатора.
Генератор Г - це перетворення, яке перетворює вхідний шум z в тензор - зазвичай зображення - х (х= G (z)). DCGAN - одна з найпопулярніших конструкцій для мережі генераторів. У мережах CycleGAN генератор виконує декілька транспонованих згортків, щоб зробити вибірку z щоб врешті-решт генерувати зображення х (Рис. 3).
Створене зображення х Потім подається в мережу дискримінантів. Мережа дискримінатора перевіряє реальні зображення в навчальному наборі та зображення, що генерується мережею генератора та дає вихід D (х), яка є ймовірністю цього зображення х реальний.
Як генератор, так і дискримінатор навчаються, використовуючи алгоритм зворотного розповсюдження для створення D (х)=1 для створених зображень. Обидві мережі навчаються поперемінним крокам, змагаючись за вдосконалення. Модель GAN зрештою конвергується та створює зображення, які виглядають реально.

GAN з успіхом застосовуються до тензорів зображень для створення аніме, людських фігур і навіть шедеврів, подібних до ван Гога. (Для інших сучасних застосувань нейронних мереж див. 6 великих успіхів, які можна віднести до штучних нейронних мереж.)
Висновки
Отже, чи глибоке навчання - це лише купа нейромереж на стероїдах? Частково.
Незважаючи на те, що більш швидкі технічні характеристики значною мірою сприяли успішному навчанню більш складних, багатошарових і навіть повторюваних нейронних архітектур, правда також, що в області чого було запропоновано ряд нових інноваційних нейронних одиниць і архітектур. зараз називається глибоким навчанням.
Зокрема, ми визначили звивисті шари в CNN, підрозділах LSTM та GAN як одні з найбільш значущих нововведень у сфері обробки зображень, аналізу часових рядів та вільного генерування.
Єдине, що залишається зробити в цьому моменті - це зануритися глибше та дізнатися більше про те, як глибокі навчальні мережі можуть допомогти нам у нових надійних рішеннях для наших власних проблем з даними.